AIエージェントの評価:実行時の観察が鍵となる
この記事は、従来のソフトウェアとは異なるAIエージェントの評価方法について解説しています。
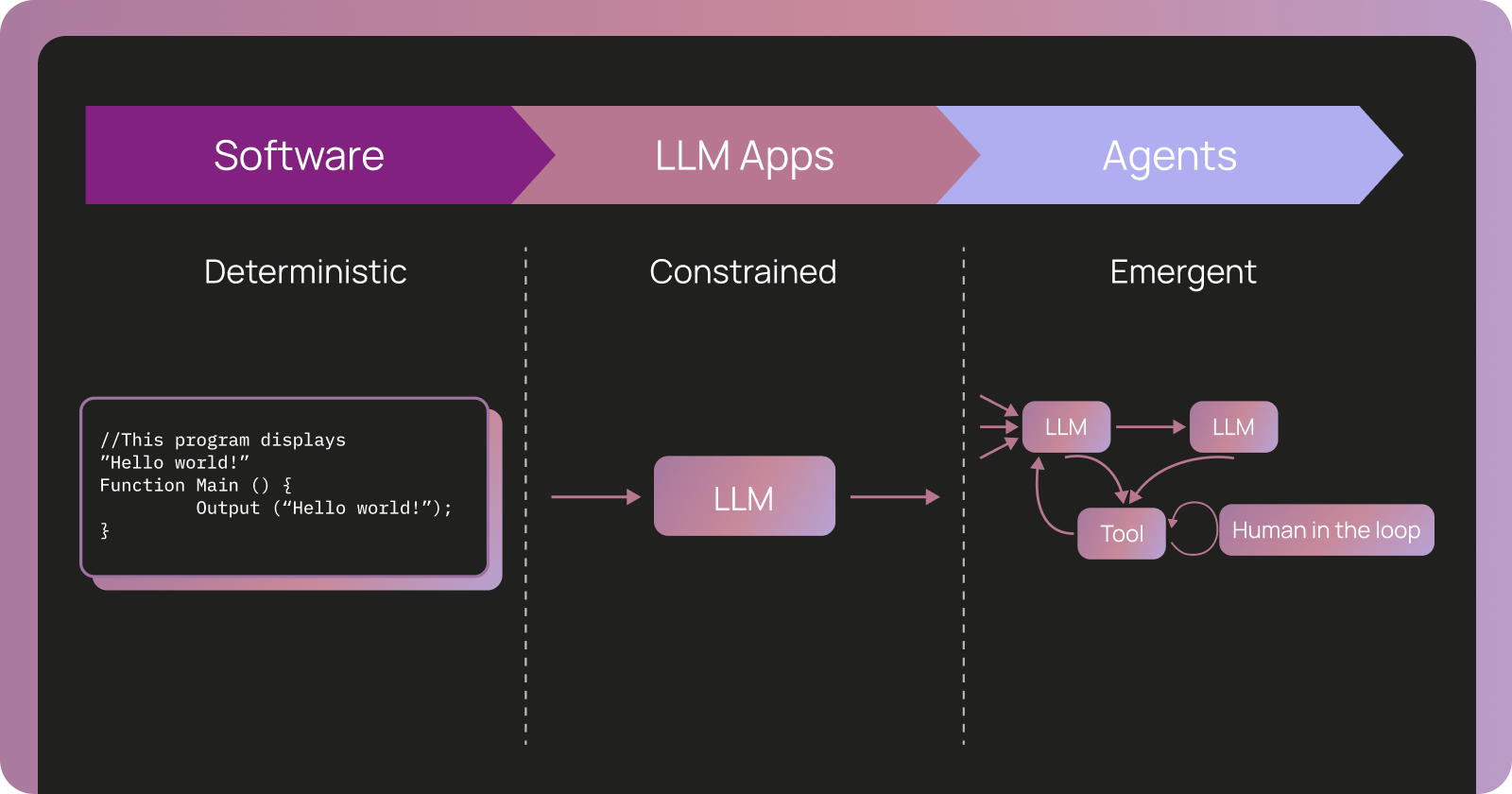
AIエージェントは複雑なタスクを実行し、その行動はコードではなくランタイムでの実行によってのみ明らかになります。そのため、従来のソフトウェアのようにコードをデバッグするのではなく、エージェントの実行履歴(トレース)を分析して評価する必要があります。
具体的には、「ラン」、 「トレース」、そして「スレッド」という3つの観測プリミティブを用いて、エージェントの行動を捉えます。「ラン」はLLMが1ステップで実行した処理、「トレース」は複数のランからなるエージェントの実行全体、「スレッド」は複数回の対話におけるエージェントの行動をまとめたものです。
これらの観測データに基づいて、個々の決定(ラン)、タスク全体の完了(トレース)、そして会話中のコンテキスト維持(スレッド)といったレベルで評価を行うことができます。
従来のソフトウェアテストとは異なり、AIエージェントの評価は実行時のみ行われ、生産環境からのフィードバックが重要となります。
背景
近年、人工知能(AI)を用いたエージェント技術が注目を集めています。エージェントは複雑なタスクを実行し、人間のように学習・適応する能力を持つため、様々な分野で活用が期待されています。しかし、従来のソフトウェアとは異なり、エージェントの行動はコードではなく実行時にのみ明らかになるため、評価方法も異なります。
重要用語解説
ラン: AIエージェントがLLM(大規模言語モデル)を用いて1ステップで実行した処理を指します。
[重要性]: エージェントの行動を分析する上で基本的な単位となります。
[具体例]: LLMにテキストを入力し、そのテキストに対する回答を生成する処理
トレース: AIエージェントが特定のタスクを実行する過程全体を示す記録です。複数のランから構成され、各ステップにおけるLLMの入力・出力、ツール呼び出しなどの情報を記録します。
[重要性]: エージェントの行動を理解し、評価するために不可欠な情報源となります。
[具体例]: ユーザーからの質問に対してエージェントがどのように回答を生成したか、どのツールを用いてどのような処理を行ったかを記録する
スレッド: 複数回の対話におけるAIエージェントの行動をまとめたものです。複数のトレースを繋ぎ合わせ、ユーザーとエージェント間のやり取り全体を把握することができます。
[重要性]: エージェントがコンテキストを維持し、長期的な対話において適切な行動をとることができるかを評価する際に重要となります。
[具体例]: チャットボットがユーザーからの質問に回答し、その後の質問に対して過去の会話内容を参照して適切な応答を提供する様子
LLM: Large Language Modelの略で、大量のテキストデータを用いて学習したAIモデルです。自然言語を理解し、生成することが得意です。
[重要性]: AIエージェントの行動の中核となる技術であり、エージェントの能力に大きく影響を与えます。
[具体例]: ChatGPT, LaMDA
今後の影響
AIエージェントの評価方法が進化することで、より信頼性の高いエージェント開発が可能になります。これは、自動化やパーソナライズ化など、様々な分野におけるAI技術の進歩に大きく貢献すると期待されます。