国立国会図書館、無料OCRアプリ「NDLOCR-Lite」を公開
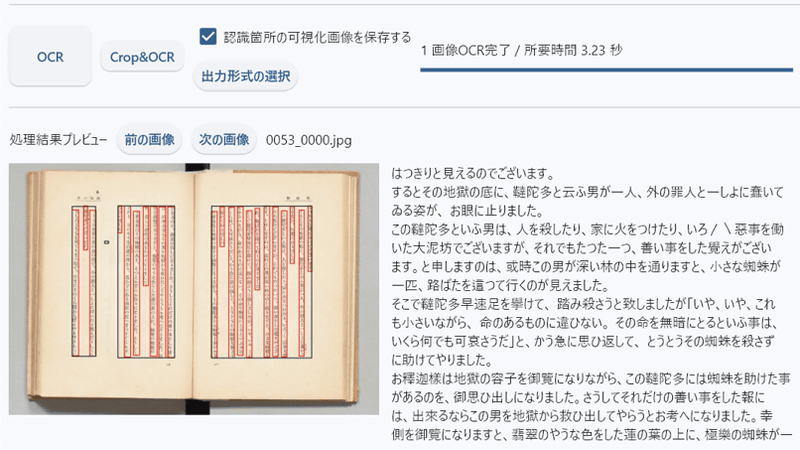
国立国会図書館のNDLラボは、デジタル画像からテキストデータを作成できるOCRアプリ「NDLOCR-Lite」を公開しました。従来の「NDLOCR」より軽量化され、一般的なPCでGPUを使用せずに利用可能です。Windows、Mac、Linuxに対応しており、日本語・手書き・縦書きも認識できます。
使い方は、配布ページからダウンロードし、起動後、「画像ファイルを処理する」をクリックしてテキスト抽出したい画像を選択。出力先フォルダを設定し、「OCR」をクリックすると、1.24秒でテキスト化されます。JSON、TXT、XML、TEI形式のファイルが保存され、プレビューも表示されます。
「Crop&OCR」機能では、画像の一部を指定してテキスト抽出でき、複数画像を一括処理することも可能です。「キャプチャモード」では、画面上の任意部分をキャプチャしてテキスト化できます。NDLOCR-LiteはCC BY 4.0ライセンスで公開されており、英文や手書き文字にも対応しています。
背景
国立国会図書館のNDLラボが開発したOCRアプリ「NDLOCR」の後継として、「NDLOCR-Lite」が公開されました。従来の「NDLOCR」はGPUが必要でしたが、NDLOCR-Liteは軽量化され、一般的なPCでも使用可能になりました。
重要用語解説
NDLラボ: 国立国会図書館の研究開発部門。デジタルコンテンツに関する研究や開発を行っている。
OCR: Optical Character Recognition (光学文字認識)。画像からテキストデータに変換する技術。
CC BY 4.0ライセンス: クリエイティブ・コモンズによる著作権許諾の一つ。作品を自由に利用、改変、配布できるが、作者へのクレジットとライセンスの表示が必要となる。
GPU: Graphics Processing Unit (グラフィック処理装置)。画像処理や計算に特化したハードウェア。
JSON: JavaScript Object Notation (JavaScript オブジェクト表記)。データの交換に広く用いられるテキスト形式。
今後の影響
NDLOCR-Liteは、誰でも無料で利用できる高機能なOCRアプリとして注目されています。文書化やデジタルアーカイブ化など、様々な分野で活用が期待されます。また、軽量化された設計により、より多くのユーザーがOCR技術を利用できるようになる可能性があります。