エージェントの「記憶」と「ハニーステーション」の重要性:オープンな仕組みでデータ主権を確保せよ
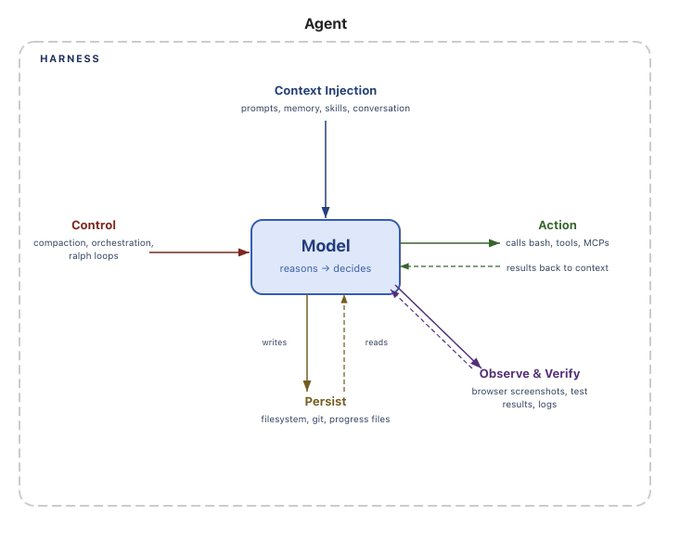
本記事は、AIエージェント構築における「エージェントハニーステーション(Agent Harnesses)」と「記憶(Memory)」の構造的な重要性について詳細に論じています。エージェントの構築方法がRAGチェーンからLangGraphを経て、現在はハニーステーションという新たな骨組みに移行している現状を説明しています。ハニーステーションは、LLMがツールやデータソースと相互作用するためのシステム全体を指し、Claude CodeやOpenCodeなどがその例として挙げられています。
特に重要な論点は、このハニーステーションが「記憶」と密接に結びついているという点です。記憶は単なるプラグインではなく、コンテキストを管理し、エージェントの振る舞いを維持するためのハニーステーションの核となる機能です。短期記憶(会話履歴)から長期記憶(セッションをまたぐ情報)に至るまで、ハニーステーションがコンテキスト管理の主要な責任を負っています。
筆者は、この記憶の管理がクローズドなAPI(例:OpenAIやAnthropicのAPI)の背後にある場合、ユーザーは自身の記憶を所有できず、プラットフォームにロックインされる危険性が極めて高いと警鐘を鳴らしています。モデル提供者は、記憶機能(ステート)をAPIの背後に隠すことで、単なるモデル提供以上の「ロックイン」効果を得ようとしており、これが業界の大きな懸念事項です。
結論として、記憶とハニーステーションは、エージェントがユーザーとのやり取りを通じて独自の「独自のデータセット(proprietary dataset)」を構築し、パーソナライズされた体験を提供するための生命線です。このデータ主権を確保するためには、ハニーステーションと記憶の両方をオープンソースかつオープンな標準(例:agents.md)に基づき、モデル提供者から独立して所有することが不可欠であると主張しています。Deep Agentsのようなオープンなソリューションの利用が推奨されています。
背景
AIエージェントの進化に伴い、単なるLLMの利用から、複数のツールやデータソースを連携させる複雑なシステム構築(エージェント構築)へと焦点が移っています。この過程で、システム全体の骨組みとなる「ハニーステーション」と、過去のやり取りを保持する「記憶」の重要性が浮上しました。これらがクローズドなAPIに閉じ込められることで、ユーザーのデータ主権が脅かされるという問題が背景にあります。
重要用語解説
- エージェントハニーステーション (Agent Harnesses): AIエージェントを構築するためのシステム的な骨組み全体を指します。LLMがツールやデータと連携し、複雑なタスクを実行するための環境や仕組みそのものです。
- 記憶 (Memory): エージェントが過去の対話や経験から学習し、それを保持・参照することで、パーソナライズされた継続的な体験を可能にする機能です。コンテキスト管理の核となります。
- ロックイン (Lock-in): 特定のプラットフォームやベンダーの技術に深く依存しすぎてしまい、他の選択肢へ移行することが極めて困難になる状態を指します。データやシステムがプラットフォームに閉じ込められるリスクです。
今後の影響
エージェントの記憶とハニーステーションのオープン化は、AI開発におけるデータ主権の確保に直結します。オープンな標準を採用することで、特定のモデル提供者に依存しない「モデルアグノスティック」なエージェント開発が可能となり、市場全体の競争促進とユーザーの利益保護に繋がると予想されます。今後の開発は、オープンな記憶システムへの移行が鍵となります。