Google、ノートPC向け軽量AI「Gemma 4 12B」を公開:エンコーダー不要で画像・音声処理を実現
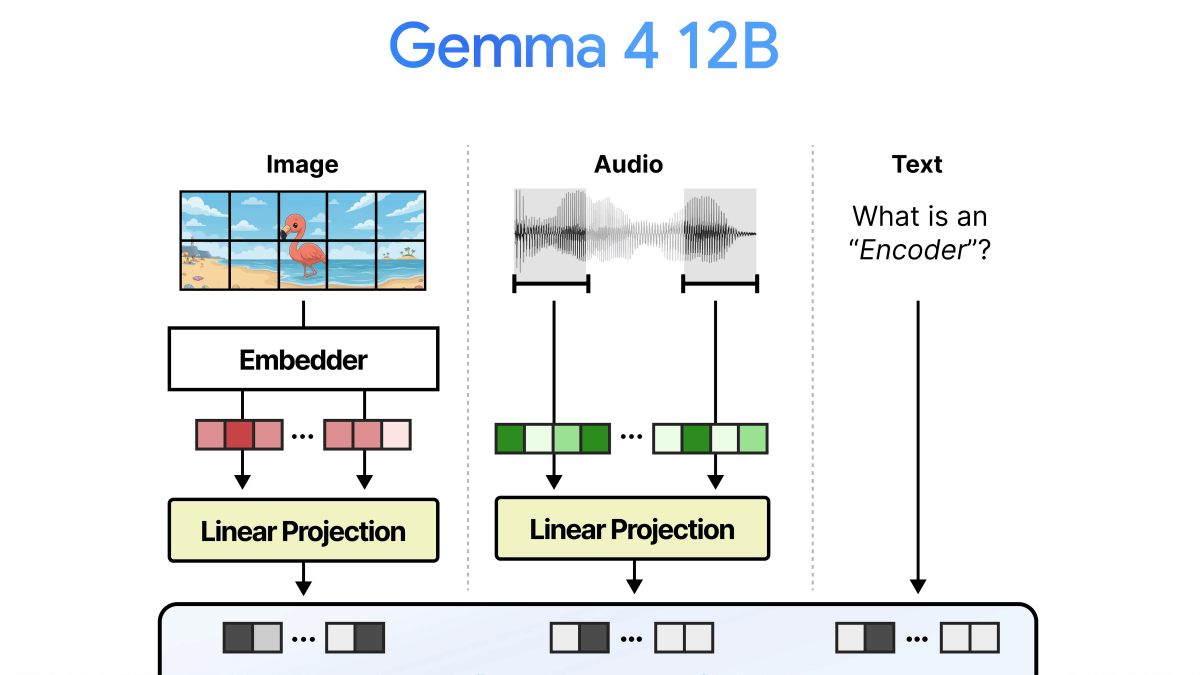
Google DeepMindは、軽量AIモデル「Gemma 4 12B」を2026年6月3日にオープンモデルとして公開しました。本モデルは、16GBのVRAMまたはユニファイドメモリを搭載したノートPCなど、ローカル環境での実行を想定しています。Gemma 4 12Bの最大の特徴は、「エンコーダー不要」で画像と音声を直接処理できるマルチモーダル設計を採用した点です。
従来のマルチモーダルモデルでは、画像や音声の入力をAIが理解しやすい「埋め込み(Embedding)」形式に変換する際に、エンコーダーという追加のAIモデルが必要でした。このエンコーダーの存在が、メモリ使用量の増加や処理の遅延を引き起こす原因となっていました。しかし、Gemma 4 12Bは、このエンコーダーを排除することで、省メモリ化と低遅延化を大幅に実現しました。
具体的には、画像処理においては、画像を48×48ピクセルのパッチに分割し、専用の埋め込みモジュール(パラメーター数3500万)を用いて処理します。音声処理に関しては、音声を40ミリ秒ごとに区切り、音の高低をトークン化することで、テキストデータと同様にLLM(大規模言語モデル)で直接処理できる仕組みを採用しています。これにより、従来の音声エンコーダー(例:Gemma 4 E2B/E4Bの3億5000万パラメーター)が不要となりました。
この軽量化された設計により、Gemma 4 12Bは、総パラメーター数の多いGemma 4 26B A4Bに近い性能を発揮しつつ、ノートPCでの実用性を高めています。本モデルはオープンモデルとして無料公開され、ライセンスはApache License 2.0です。
背景
AIモデルのマルチモーダル化が進む中で、画像や音声といった非テキストデータを効率的に処理し、ローカルデバイスで動作させることは大きな課題でした。従来のモデルは、データ変換のための「エンコーダー」が必須であり、これがメモリ負荷や処理遅延の原因となっていました。本ニュースは、この課題を解決した新しいアーキテクチャの提示です。
重要用語解説
- エンコーダー: 画像や音声をAIが処理できる形式(埋め込み)に変換する役割を持つAIモデル。従来のマルチモーダルモデルでは必須でしたが、Gemma 4 12Bではこれを排除しました。
- マルチモーダルモデル: テキストだけでなく、画像、音声など複数の種類のデータ(モダリティ)を同時に理解し、処理できるAIモデルのこと。
- 埋め込み(Embedding): 画像や音声を、AIが数学的に処理しやすい数値のベクトル形式に変換したデータのこと。モデルの入力層として使用されます。
今後の影響
ローカルPCでのAI処理のハードルを大きく下げ、より多くのユーザーが高性能なAIを日常的に利用可能にします。特に、エンコーダー不要という設計は、エッジデバイスや組み込みシステムへのAI実装を加速させ、AIの普及に貢献すると予想されます。今後のAI開発の標準的な設計指針となる可能性があります。