ChatGPTの「記憶」機能が進化しすぎる懸念:パーソナライズされた情報過多がもたらすリスク
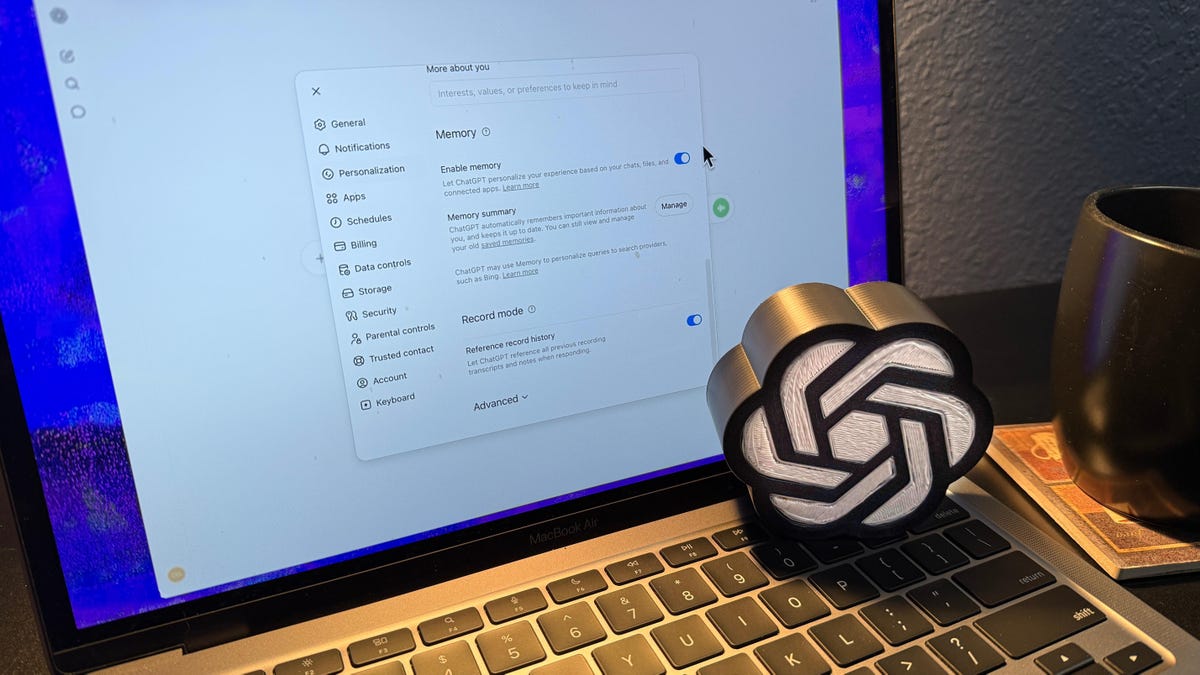
本記事は、OpenAIが提供するチャットボット「ChatGPT」の新しいメモリ管理機能(Dreaming V3)について詳細に分析しています。この機能は、単なる過去の事実リストを超え、ユーザーとの全てのやり取り履歴、明示的な指示、個人的な制約、さらには無意識の好みまでを背景で自動的に学習・統合し、「ドシエ」のような包括的なプロファイルを構築します。
2024年に導入された初期の「メモリ」機能が単なる事実リストに留まり、時間の経過とともに陳腐化するという問題があったのに対し、2025年には「Dreaming」という概念が加わり、モデルが背景で履歴を参照するようになりました。そして現在(2026年)、V3バージョンでは、この自動的なデータ合成能力が飛躍的に向上しています。
OpenAIによると、ChatGPTは過去のやり取りから得たコンテキスト情報を維持し、複雑な多セッション・多層的な長期プロジェクトを追跡することが可能となり、ファクトタスクリコール成功率が2024年の41%から82%に、継続的な正確性が9%から75%に向上したとされています。この進化は、計算コストの5倍削減という技術的ブレイクスルーによって実現し、PlusおよびProティアの有料ユーザーに提供されつつあります。
しかし筆者は、この高度な記憶機能に対し強い懸念を表明しています。なぜなら、AIが生成する「記憶」や推論が常に正確であるとは限らないからです。記事内で示された例では、筆者が一度も使用したことのない「Home Assistant」の利用経験までChatGPTが誤って主張しており、これは単なる事実の欠落ではなく、パーソナルなレンズを通して世界観をフィルタリングしすぎる危険性を示しています。
ユーザーは設定からメモリ機能をオフにしたり、保存された記憶を手動で削除したりできますが、完全に情報を消去することは困難であり、また安全機能のための限定的なコンテキスト利用は継続されるため、情報の管理とプライバシーの完全なコントロールは難しい状況です。筆者は、この仕組みが「自分自身を理解している」という誤解を生み出し、ユーザーの真の自己像とは異なるプロファイルをAIに構築してしまう点に強い問題意識を持っています。
背景
ChatGPTは当初、チャットセッションごとに独立した記憶しか持っていませんでした。2024年頃から「メモリ」機能が導入され、過去の会話履歴を参照できるようになりましたが、情報の陳腐化や正確性の維持に課題がありました。本記事で語られるDreaming V3は、この問題を解決し、AIがユーザーの行動パターンを深く学習する段階への進化を示しています。
重要用語解説
- ChatGPT: OpenAI社が開発した大規模言語モデル(LLM)を搭載した対話型AIチャットボット。会話履歴に基づき応答を生成し、近年は高度な「記憶」機能を持つようになった。
- メモリ (Memories): ChatGPTがユーザーとの過去のやり取りから自動的に収集・統合する個人情報や事実のデータベース。単なる記録ではなく、AIの推論に組み込まれるコンテキストとして機能する。
- Dreaming V3: OpenAIが提供する最新の記憶管理システム(バージョン3)。背景でチャット履歴全体を分析し、ユーザーに関する包括的かつ高度なプロファイルを自動的に構築・更新する能力を指す。
今後の影響
この進化はAIのパーソナライゼーションと実用性を飛躍的に高め、より複雑な長期プロジェクト管理や専門的なアシスタントとしての利用を可能にします。しかし同時に、誤った記憶が「真実」として扱われるリスクや、ユーザーが意図しない形でデータが恒久的に蓄積されるプライバシー上の懸念が高まり、今後のAI倫理およびデータガバナンスの議論を加速させるでしょう。